


Interoperability For Modular Blockchains: The Lagrange Thesis
June 19, 2023

Since protocols like Celestia and EigenLayer triggered debate around decoupling blockchains’ execution, settlement, sequencing and data availability layers, “modular blockchains” have become every crypto-enthusiast’s favorite topic. And while proponents of the modular thesis argue away in favor of a future where many (specialized) blockchains co-exist, the billion-dollar question is: “How exactly do we plan to connect these chains?”
This isn’t a trivial question, especially since interoperability between blockchains provides many benefits. There are existing interoperability solutions, such as messaging protocols and bridges, but their current implementations have drawbacks that limit their ability to connect an increasingly fragmented group of specialized execution and settlement layers.
The Lagrange Protocol is a new interoperability solution that helps protocols bypass many of those limitations and unlocks the full benefits of cross-chain interactions for decentralized applications. In this article, we explore how ZK MapReduce (which we introduced previously) contributes to Lagrange’s vision of trustless, secure, scalable, and efficient interoperability for modular blockchains and unlocks novel, exciting use cases for developers and users.
Modular blockchains: a short primer
A modular blockchain separates the functions of execution, consensus, settlement, and data availability. Whereas monolithic blockchains coordinate these activities on the same layer, modular blockchains handle some of these tasks and outsource the rest to other blockchains. This architecture — inspired by ideas from modular design — makes modular blockchains more flexible and scalable than their monolithic counterparts.
Modular blockchains are also easier to deploy/bootstrap and thus attractive to developers wanting to scale throughput (transactions per second) for applications but lack resources to build application-specific blockchains from scratch. With modular blockchain platforms, developers can focus on building highly scalable execution layers for dapps while relying on a more secure blockchain for security (an approach increasingly described as “rollups-as-a-service”).
Modular blockchains help scale TPS horizontally by creating dedicated blockspace and enable applications like high-frequency trading, gaming, and social that require high-throughput, low-cost computation (something monolithic blockchains rarely provide). But the shift to modular blockchain architectures also creates new problems which — if handled improperly — could entirely erode the benefits of “building modular”.

Understanding the drawbacks of modular blockchains
Since the LazyLedger whitepaper first outlined the modular thesis, many teams have been building core infrastructure to ease the creation of modular blockchains. Notable examples include rollups-a-service-platforms (Sovereign Labs, Caldera, Eclipse, Rollkit, Dymension) and data availability layers (EigenLayer, Celestia, Avail). Consequently, the barrier to deploying new application-specific blockchains to scale web3 dapps has dramatically reduced.
Admittedly, the ability to “deploy a rollup in one click” is great; but a world in which hundreds and thousands of blockchains co-exist has some drawbacks. One of those drawbacks — which we describe in detail in this section — is that of interoperability.
Suppose Bob (a developer) wants to create an application-specific rollup to scale transactions for a new DeFi app, which we’ll call BobDEX. Bob starts out using Celestia for data availability/consensus and Ethereum for canonical bridging (settlement), but pivots to a “multichain” strategy and ends up launching instances of the DEX on a dozen more other application-specific rollups.
Now blockchains have been described elsewhere as “islands” because they lack native infrastructure for sharing value (assets) and information (state). Adopting a modular blockchain architecture — like BobDEX does — compounds the problem of interoperability further by fragmenting state and liquidity across multiple execution and settlement layers.
Let’s briefly address these two problems:
1. Fragmentation of state: In a modular blockchain architecture where an application’s state is stored on different execution layers, retrieving and verifying that data is more difficult. Applications running on a monolithic blockchain don’t have this problem since all of the contract states (current and historical) are stored on the same network.
As we move into a cross-chain future (where a single application can exist on a number of Layer 1 (L1), Layer 2 (L2), and Layer 3 (L3) blockchains), fragmentation of state may have even broader implications. For example, it becomes difficult to build applications based on complicated relationships between the state of different smart contracts if each contract is deployed to a different chain.
A simple example is a cross-chain lending protocol that would allow users to lock collateral on a source blockchain and borrow tokens on a target blockchain. Here, smart contracts running on two different chains must reach consensus on certain information, such as whether the user locked tokens. This is difficult to do because, as we explained previously, blockchains are independent “silos” incapable of exchanging data.
2. Fragmentation of liquidity: Liquidity is the ease and efficiency of converting an asset to fiat or another asset without significantly impacting its price. Liquidity matters for DeFi applications because it influences how much slippage users experience, especially on large trades.
DeFi protocols deployed to a single, monolithic chain have few issues with liquidity as all users transact on the same network. In comparison, a DeFi application spanning multiple chains will have lower liquidity on some chains compared to others. And since assets cannot flow between blockchains (per the interoperability problem), DeFi users are limited to the liquidity available on a particular chain.
Besides degrading overall user experience, poor liquidity can also stunt multichain growth for DeFi projects. Specifically, some users may avoid using a DeFi application on a low-liquidity blockchain for fear of high slippage on trades or inability to exit a large position. To use an earlier example: Alice may prefer to use BobDEX on Ethereum (because of its high TVL) to using the BobDEX on NEAR (because of its low TVL).

Solving interoperability problems for modular blockchains
“What are the most important problems in your field, and why aren’t you working on them?” — Richard Hamming
By now, many people agree the proliferation of modular blockchains is inevitable. But a modular future isn’t ideal if it doesn’t guarantee the qualities that set web3 apart from web2: decentralization, composability and interoperability.
From previous examples, we’ve seen how applications lose composability and interoperability by moving away from a shared state layer. We’ve also seen how expanding to new settlement (or canonical bridging) layers fragments liquidity and network effects for applications, resulting in a poor user experience.
All of these are stumbling blocks to adoption of modular blockchains and have raised concerns about the viability of a multi-chain future. Recognizing the problem, a number of projects are working on solutions that improve interoperability between modular blockchains and mitigate problems around fragmentation of state and liquidity.
Some of these include:
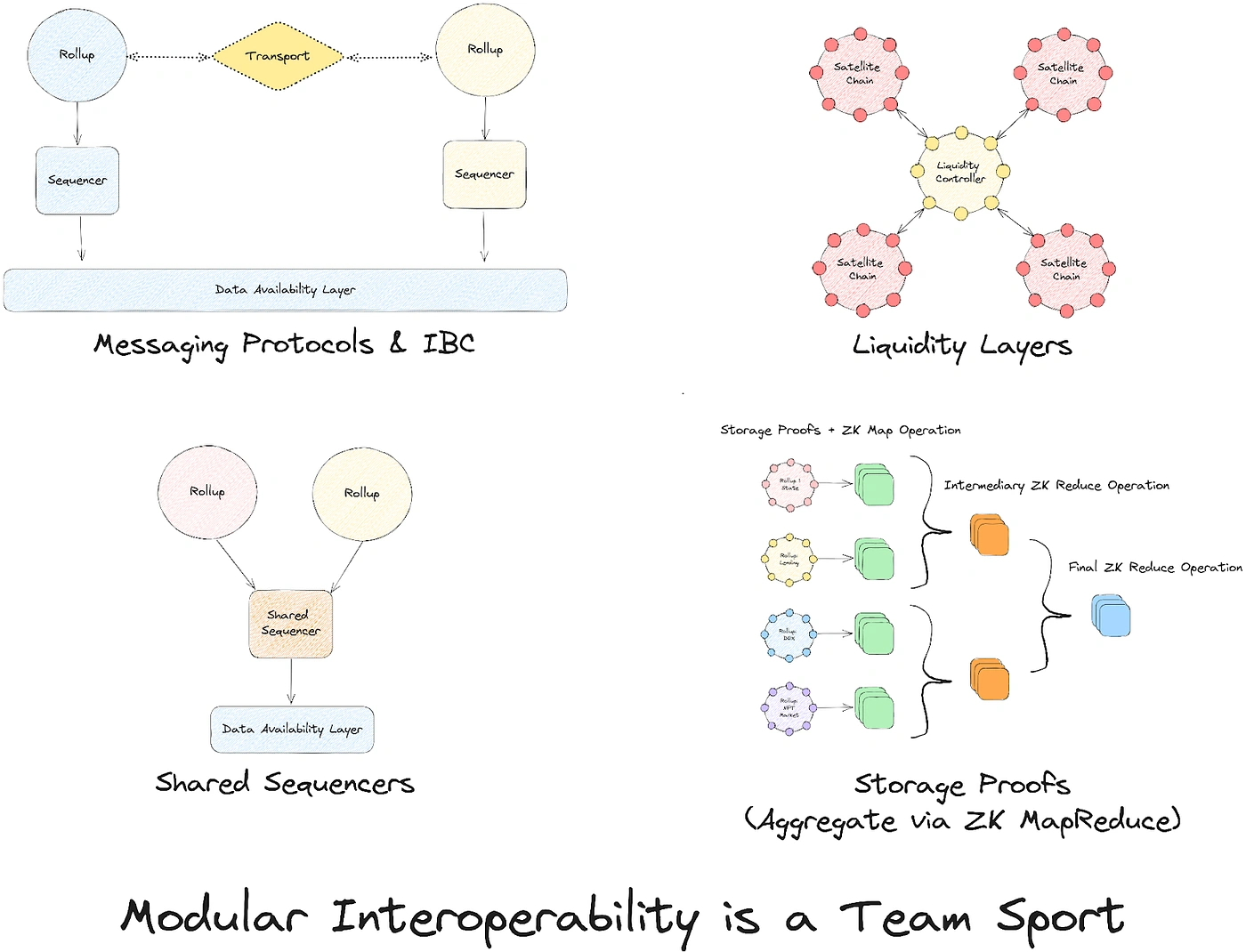
Shared sequencing networks
Espresso and Astria are building a decentralized network of sequencers that can be shared by multiple modular rollups. Sometimes described as “lazy sequencers”, a shared sequencer set orders transactions from different rollups into a single “mega block” and submits to a data availability layer like Celestia without executing rollup transactions. Individual rollup nodes retrieve blocks from the data availability layer (or from the sequencer network) and execute relevant transactions to update the rollup’s state.
Shared sequencers enable new execution layers to achieve decentralization, censorship resistance, and fast finality from inception (without having to run in-house sequencer infrastructure or spend effort on bootstrapping a decentralized sequencer set). A shared sequencer network also improves composability and interoperability between rollups by enabling atomic inclusion of cross-chain transactions.
As explained previously, a shared sequencer produces blocks that include transactions to be executed on different rollups. Thus it can guarantee that a transaction on rollup #1 is included in a block on the condition that the block includes another transaction on rollup #2. This unlocks novel use-cases for interchain communication, such as cross-chain arbitrage trades and asset bridging.

This is an oversimplification, however. For a deep dive into the mechanics of shared sequencing, we refer readers to Maven11’s systemization of knowledge (SoK) on shared sequencing that covers various benefits and attributes of a shared sequencer, including interoperability. Succinct Labs also has an interesting proposal for synchronous execution of atomic transaction bundles between rollups sharing a sequencer.
“Shared sequencing is an important part of the modular stack, reducing the effort to launch rollups while allowing them to be decentralized by default.” — Josh Bowen, Astria Founder
Messaging protocols
Generalized messaging protocols enable the transfer of arbitrary messages between different chains. At a high level, messaging protocols solve problems around fragmentation of state by verifying and relaying packets of data between chains. This allows chains that would be otherwise siloed to become aware of each other’s states, enabling more data-rich use cases than asset bridging or cross-chain atomic transactions.
Cross-chain lending (which we described previously) is an example. To enable this use case, a developer could integrate with a messaging framework like LayerZero, Axelar, Hyperlane, or Wormhole to relay information about on-chain operations (opening or closing a collateral position) between instances of an application running on the source and destination chains.
For modular blockchains, where state is split across different layers, messaging protocols improve connectivity and composability. For instance, Hyperlane has already launched integrations to allow users to send messages from both sovereign rollups on Celestia and FuelVM rollups.
A popular approach to standardizing cross-chain messaging is the Inter-Blockchain Communication Protocol (IBC). While IBC became popular from its adoption in the Cosmos ecosystem, its design is extensible to other chains as well.
Polymer Labs is building a “modular IBC transport hub” that combines IBC with zero-knowledge cryptography and a Tendermint-based consensus engine to facilitate seamless, trust-minimized communication between modular chains. Their ZK-IBC design aims to create a modular standard for allowing different blockchain protocols to support messaging through consensus verification, without relying on trusted third parties.
“ZK-IBC, or a circuit implementation of the IBC transport layer, will enable both native IBC within ZK-rollups as well as trust-minimized communication for blockchains in the modular ecosystem”. — Bo Du, Polymer Co-Founder
Cross-chain liquidity routers
Liquidity routers enable users to transfer assets between a pair of blockchains—for example, a user can interact with BobDEX on a Caldera rollup by moving their assets from an Eclipse rollup using a liquidity bridge. Liquidity routing infrastructure solves a pressing problem for the modular ecosystem: poor user experience when trying to interact with applications on new chains.
A robust cross-chain liquidity layer reduces the difficulty of bootstrapping meaningful economic activity on new chains by providing an easy way to access liquidity from other ecosystems (mitigating the issue of fragmented liquidity). This is where solutions like Catalyst (an Automated Market Maker (AMM) for cross-chain asset swaps and asset pooling) come into the picture.
“The future will have millions of chains, and very few people in the space are actively trying to build at the scale required in that future…In that future, liquidity will increasingly be fragmented—which is why we're building Catalyst to unify liquidity into a shared layer. — Jim Chang, Catalyst Co-Founder
Analyzing existing interoperability solutions
Shared sequencers, messaging protocols, and liquidity routers are vital for supporting foundational interoperability between modular blockchains, such as asset transfers and simple message passing. But they are largely designed to enable performant 1-to-1 interoperability — that is, cross-chain interactions between pairs of protocols operating in the same or different ecosystems.

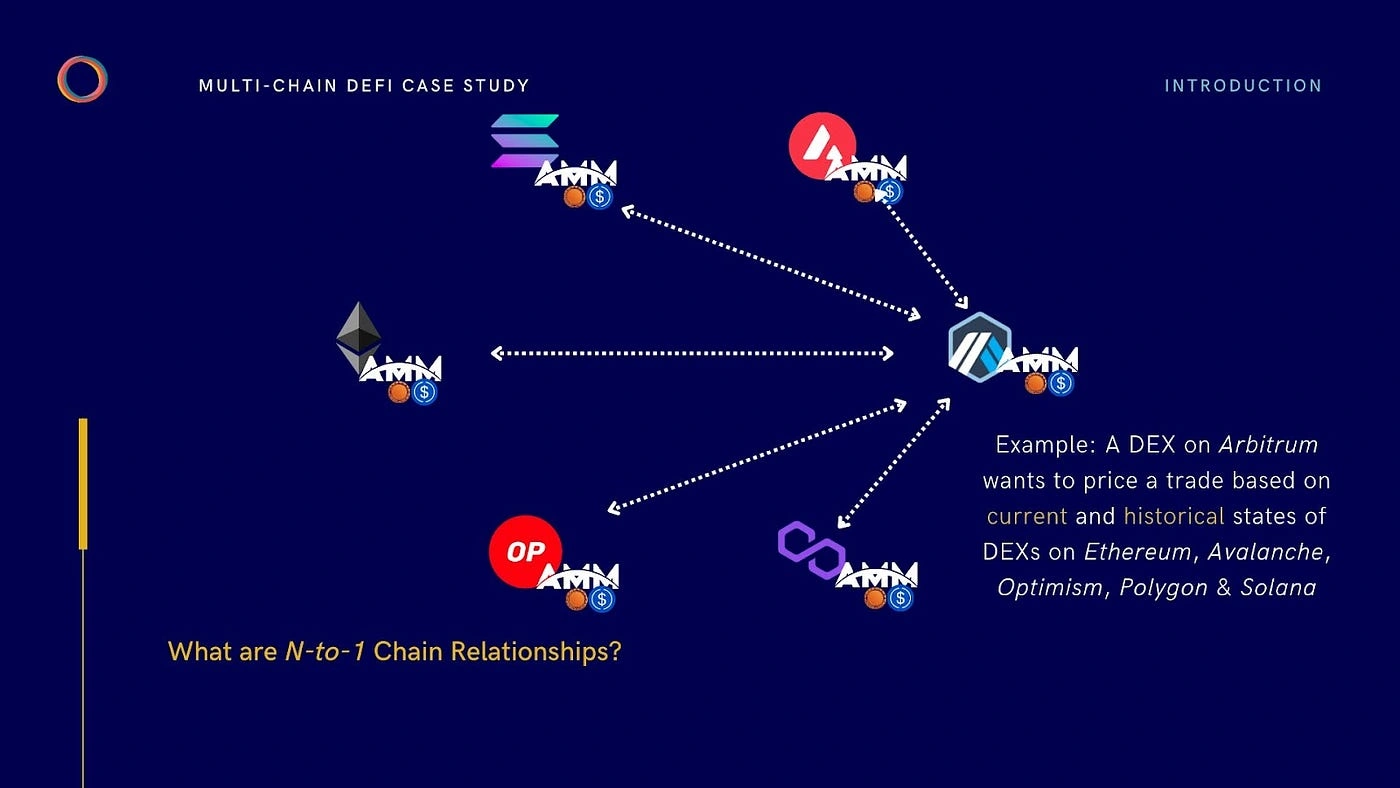
What do we mean? In their current form, the aforementioned solutions are not optimized to support applications whose business logic requires access to multiple concurrent contract states spanning an increasingly fragmented group of execution and settlement layers. We describe this form of interoperability as n-to-1 interoperability as it requires creating relationships between an unbounded number of chains.
To illustrate this idea, consider the case where Bob wants to create a “cross-chain DEX” that enforces a global price on asset swaps on every chain where it is deployed. AMM-based DEXes price swaps using a so-called “conservation function” that takes into account the liquidity of token pairs involved in a trade. A cross-chain DEX would, therefore, need to track the state of liquidity across all deployments and use the information to calculate prices for token swaps.
One might naturally want to integrate with a messaging protocol to relay changes in the liquidity of a DEX on one chain to DEXes on other chains, every time a swap, deposit, or withdrawal occurs. But this approach incurs significant cost and latency and is quite unfeasible to implement in production.
For instance, if BobDEX operated on five chains and a swap occurred on one chain, we would need four separate transactions to relay this event to other deployments before they could adjust prices. To put it formally: as the number of chains that an application is deployed on, n, grows the messaging complexity to communicate between all instances grows as n2.
This mechanism (using oracles and messaging protocols) is also subject to hidden failure-modes. An example: relayers/oracles can censor cross-chain messages or relay incorrect data, in which case the remaining BobDEX applications would operate using stale/incorrect prices.
As you can see, message-passing or asset-bridging frameworks are essential but don’t alone solve interoperability for multichain applications like BobDEX. What Bob and team need is an interoperability solution with the following features:
- The ability to prove the state of a smart contract on one or more chains to smart contracts on n other chains without introducing any trust assumptions
- The ability to prove cross-chain contract states at scale without increasing latency or costs or degrading overall user experience
- The ability to perform computation on cross-chain state data in a trust-minimized, secure, and efficient manner
The last point (computation on on-chain data) is important in the context of building applications with multichain relationships. As an example, a message relayer can prove the amount of liquidity on a given BobDEX instance to a specific BobDEX on a different rollup, but lacks the ability to derive any property about the chain besides the current state. The DEX in question cannot, for instance, use the information to run complex pricing algorithms, such as calculating the time-weighted average price (TWAP) of an asset based on historical liquidity of different chains.
ZK MapReduce and the modular blockchain interoperability stack
Seeing as we’ve taken pains to highlight the opportunities for expanding the scope of interoperability infrastructure, surely we must have a way to improve them? Why, yes we do!
Lagrange Labs builds infrastructure to scale trustless interoperability through improving the security of how state is proven between chains and expanding the types of computation that can be run on top of cross-chain states. More specifically, Lagrange Labs’ suite of solutions provide a way to meaningfully enhance the security of existing messaging protocols and bridges and expand how cross-chain data can be used within applications.
What’s better, Lagrange Labs does this all without burdening users and developers with additional trust assumptions. Lagrange Labs’ flagship product for cross-chain computation is ZK Big Data: a novel proof construction built for generating large (batched) storage proofs and executing distributed computation secured by zero-knowledge cryptography.
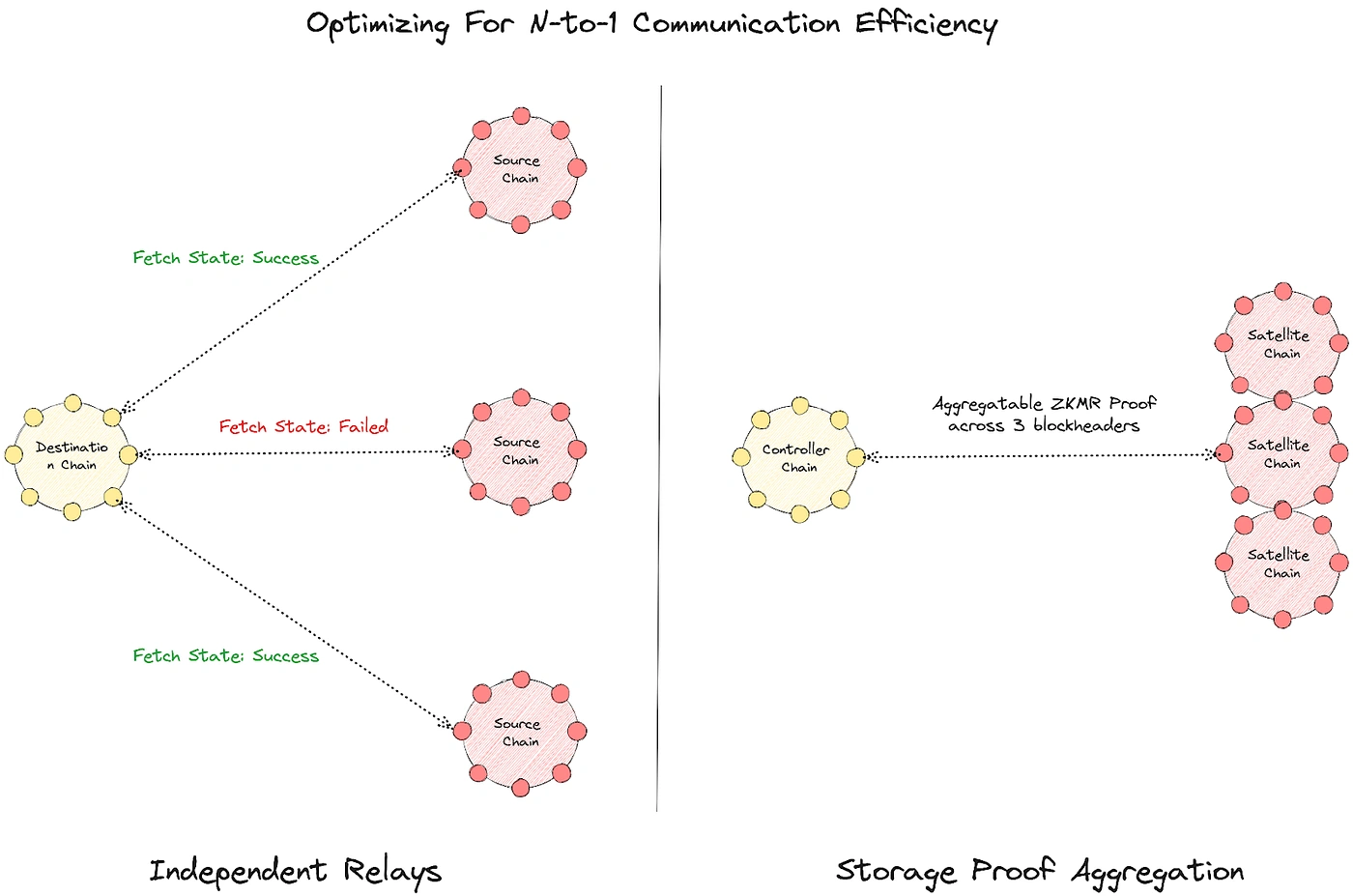
ZK MapReduce, the first product in the Lagrange ZK BigData stack, is a distributed computation engine (based on the well-known MapReduce programming model) for proving results of computation involving sizable sets of multi-chain data. For example, a single ZKMR proof can be used to prove changes in the liquidity of a DEX deployed on 4–5 chains over a specified time window.
ZK MapReduce proofs are designed to make it easy to combine multi-chain state dataframes into a single proof. This property allows anyone to prove the state of smart contracts on n source chains to a smart contract on a destination (n+1) chain without interacting with any other chain beyond the destination chain. Contracts can easily verify computations run on cross-chain states by calling Lagrange’s public verifier contract on-chain. The workflow looks like this:
- The client contract passes the public statement — the data being proved — and the accompanying validity proof to the verifier contract
- The verifier contract returns a true or false value to confirm if the storage data and computation are valid with respect to the proof (or not)
With its current architecture, the Lagrange ZK Big Data stack can support generating proofs that simultaneously prove both contract storage and computation:
1. Contract storage: A Lagrange state proof can reference the storage contents of one or more contracts on a given chain. This requires passing the state root (derived from the block header), storage slot values, and a Merkle Patricia Trie (MPT) inclusion proof into a proving circuit and generating a validity proof. (The MPT proof is needed to confirm that those values are part of the chain’s state tree)
2. Computation: A Lagrange state proof can reference the result of computation performed using storage slot values derived from contracts on specific chains. Now this is where ZK MapReduce comes into the picture — after proving that certain contract values exist w.r.t. to specific block headers, we can execute arbitrary MapReduce computation on those values.
In this case, state proofs verify that (a) a set of historical block headers are valid w.r.t. the input block headers and contain certain contract values and (b) computation on those contract values provides a specific result. This aspect of Lagrange’s interoperability infrastructure has a unique (and largely underappreciated) benefit: the ability to prove complex multi-chain (n-to-1 chain) relationships involving both present and historical data.
Consider the previous example of a cross-chain DEX designed to price swaps based on liquidity data aggregated from different chains. We’ve already discussed that existing cross-chain communication mechanisms struggle to enable this use case without incurring significant overhead and inheriting weak security properties.
In comparison, Lagrange — via ZK MapReduce — can support this use case without compromising on cost, security, and efficiency. Here’s a hypothetical two-step workflow to show how this is possible:
1. Proof generation: Liquidity data for each DEX is proven by verifying both cross-chain contract state and the result of computation on that state within a ZKMR proof.
2. Proof verification: After the proof is generated, it can be submitted to the destination chain to show correctness of computation that produced the requested value (total DEX liquidity across all deployments).The submission of the proof can be handled by any transport layer ranging from oracles to messaging protocols to automated keepers.
In practice, Lagrange state proofs (including proofs for ZK MapReduce computation) can be requested using the Lagrange SDK. This makes it easy for applications to generate and integrate proofs into any existing infrastructure, without requiring specialized proving systems or hardware.
“As the world of blockchains grows increasingly modular, more and more chains are set to join the fray. Cross-chain interoperability is at the heart of the modular thesis, and while a shared DA layer helps alleviate some of this, it doesn’t resolve the issue completely. The cross-chain interoperability protocols, used to maintain connectivity across chains, should in my mind, focus on security above all. The most likely way forward is with zero-knowledge light client verification (or cross-chain state/storage proofs via a committee), as well as strong economic security guarantees. The economic bonds of large amounts of staked collateral can be used to achieve strong attestation to finality. Two of the major issues that still remain to be solved are the scalability of ZK via improvements such as ZK MapReduce & recursion, as well as lowering the trust from social slashing.”
— Rain&Coffee, Maven11 Researcher & Investor
The future of interoperability for modular blockchains
As modular blockchains proliferate, interoperability is required to ensure seamless integration and composability for applications running on different chains. This article has explored some solutions to the problem of interoperability in the modular ecosystem (shared sequencers, message relayers, liquidity routers) and discussed their individual strengths and weaknesses.
We also explained how Lagrange’s ZK MapReduce overcomes limitations of existing interoperability protocols and expands the ways applications can consume cross-chain state data. Future articles will treat this topic in more detail, focusing on more exciting possibilities unlocked by ZK MapReduce: cross-chain yield farming, multichain asset pricing for DeFi protocols, cross-chain airdrops, and more.
Lagrange is under active development and poised for a testnet launch in coming months. Are you interested in building cross-chain applications that can trustlessly access historical on-chain data and perform verifiable computation on multi-chain states? Reach out to the team, and let’s chat!
Website | Twitter | Join our ecosystem
Acknowledgements
Thank you to the founders, investors and researchers working in the modular cross-chain space who provided thought-provoking conversation and feedback on this article.
This article was made possible through collaboration with Bo, Josh, Jim and Rain&Coffee.

